前書き
機械学習の実験管理ツール、MLflow がパラメータ管理に非常に便利なので布教のために書く。 実験たくさんすると、どのモデルの性能が良かったのかわからなくなるので、そんなときに役立つツールです。
導入方法紹介!とかの記事はよく見るけど、何が便利なのかについて触れてる記事って少ない気がする。。。 というわけで導入手順は公式ドキュメントか他の記事にお任せするとして、便利そうなイメージを持ってもらうことを狙って書いていきます。
ポイント
- 普段の学習にたった 2 行追記するだけで、実験パラメータが自動記録される。
- 実験パラメータ、実験結果の比較が簡単にできる。
- 各実験に対してメモを記入できる。
- 各実験のモデルが自動保存される。 (うまくいかなかったので本稿では取り上げていません。)
前提
MLflow のトラッキングサーバーが既に立ち上がっている前提で進めます。 私は GCP の無料枠で立ち上げました。GCP の無料インスタンスの 600MB メモリーだと、OOM が頻繁に発生して使い物にならなかったのでスワップを設定しています。
とはいえ、とりあえず試す分にはローカルのトラッキングサーバーで十分と思います。
- version
- MLflow: 1.14.0
- Tensorflow: 2.4.1
- keras: 2.4.3
使い方
初期画面
ブラウザから確認できる MLflow の初期画面は以下です。
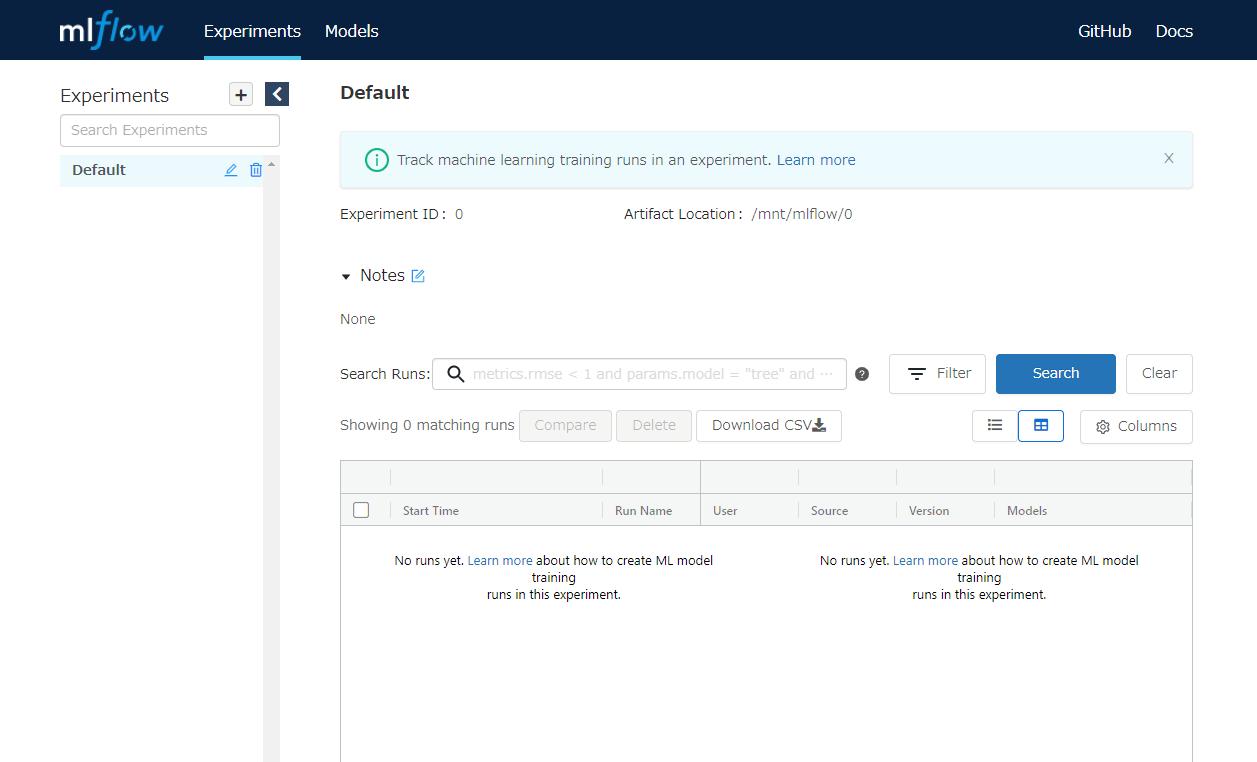
Python でおこなった学習の結果が自動でここに記録されていきます。
概念
MLflow の管理単位の概念を簡単に。
- Experiment: 複数の実験記録をまとめる単位 (プロジェクト的な立ち位置?)
- run: 1 つの実験記録の単位。モデルの学習 1 回分(1fit 分)が記録される。必ず Experiment に属する。
1 つの Experiment に対して、複数の run が記録されます。
これを複数人で使う場合にどのように分けるのが良いのかがいまいち分からない。。。Experiment で分けるのがいいのかな。
自動記録
MLflow には autolog 機能があり、これを使うと以下のライブラリは自動でパラメータを記録できます。有名なライブラリは網羅されていて、開発努力がすごいなと思います。なお、autolog は現時点で実験的なサポートであるため、今後仕様変更がある場合があります。公式 Document
- Scikit-learn
- TensorFlow and Keras
- Gluon
- XGBoost
- LightGBM
- Statsmodels
- Spark
- Fastai
- Pytorch
autolog は最短 2 行で有効にできます。
import mlflow
mlflow.autolog()
Example
探したら公式の example があったので流用。keras で試します。autolog には自動で全ライブラリに対してログを有効にする方法(mlflow.autolog())と、ログをとるライブラリを自分で指定する方法(例: mlflow.keras.autolog())があります。デモの都合上、今回は mlflow.tensorflow.autolog()を使います。公式 example
"""Trains and evaluate a simple MLP
on the Reuters newswire topic classification task.
"""
import numpy as np
import keras
from keras.datasets import reuters
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.preprocessing.text import Tokenizer
# MLflowの設定
import mlflow
mlflow.set_tracking_uri("https://xxxx.xx/") #トラッキングサーバーの設定
mlflow.tensorflow.autolog(every_n_iter=1) # eveny_n_iterで何epoch毎に記録を取るか設定。デフォルトは100の為、数epochだと学習曲線が書けない。
# パラメータ
max_words = 1000
batch_size = 64
epochs = 20
# データ読み込み
print("Loading data...")
(x_train, y_train), (x_test, y_test) = reuters.load_data(num_words=max_words, test_split=0.2)
print(len(x_train), "train sequences")
print(len(x_test), "test sequences")
num_classes = np.max(y_train) + 1
print(num_classes, "classes")
print("Vectorizing sequence data...")
tokenizer = Tokenizer(num_words=max_words)
x_train = tokenizer.sequences_to_matrix(x_train, mode="binary")
x_test = tokenizer.sequences_to_matrix(x_test, mode="binary")
print("x_train shape:", x_train.shape)
print("x_test shape:", x_test.shape)
print("Convert class vector to binary class matrix " "(for use with categorical_crossentropy)")
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
print("y_train shape:", y_train.shape)
print("y_test shape:", y_test.shape)
#モデル作成
print("Building model...")
model = Sequential()
model.add(Dense(512, input_shape=(max_words,)))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation("softmax"))
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
#学習
history = model.fit(
x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_split=0.1
)
score = model.evaluate(x_test, y_test, batch_size=batch_size, verbose=1)
print("Test score:", score[0])
print("Test accuracy:", score[1])
普段の学習に追加したのは、ハイライトした 3 行のみです。非常に簡単。“mlflow.set_tracking_uri()“トラッキングサーバーをローカルに立てた場合は、そちらを設定してください。(デフォルトは http://localhost:5000/のはず。)
今回は batch_size を変更して、合計 2 回学習を回しました。その結果が自動でトラッキングサーバーに記録されます。

一覧でパラメータを比較でき、また絞り込み検索も可能です。どの実験がうまくいったかすぐ確認できます。
記録内容の詳細
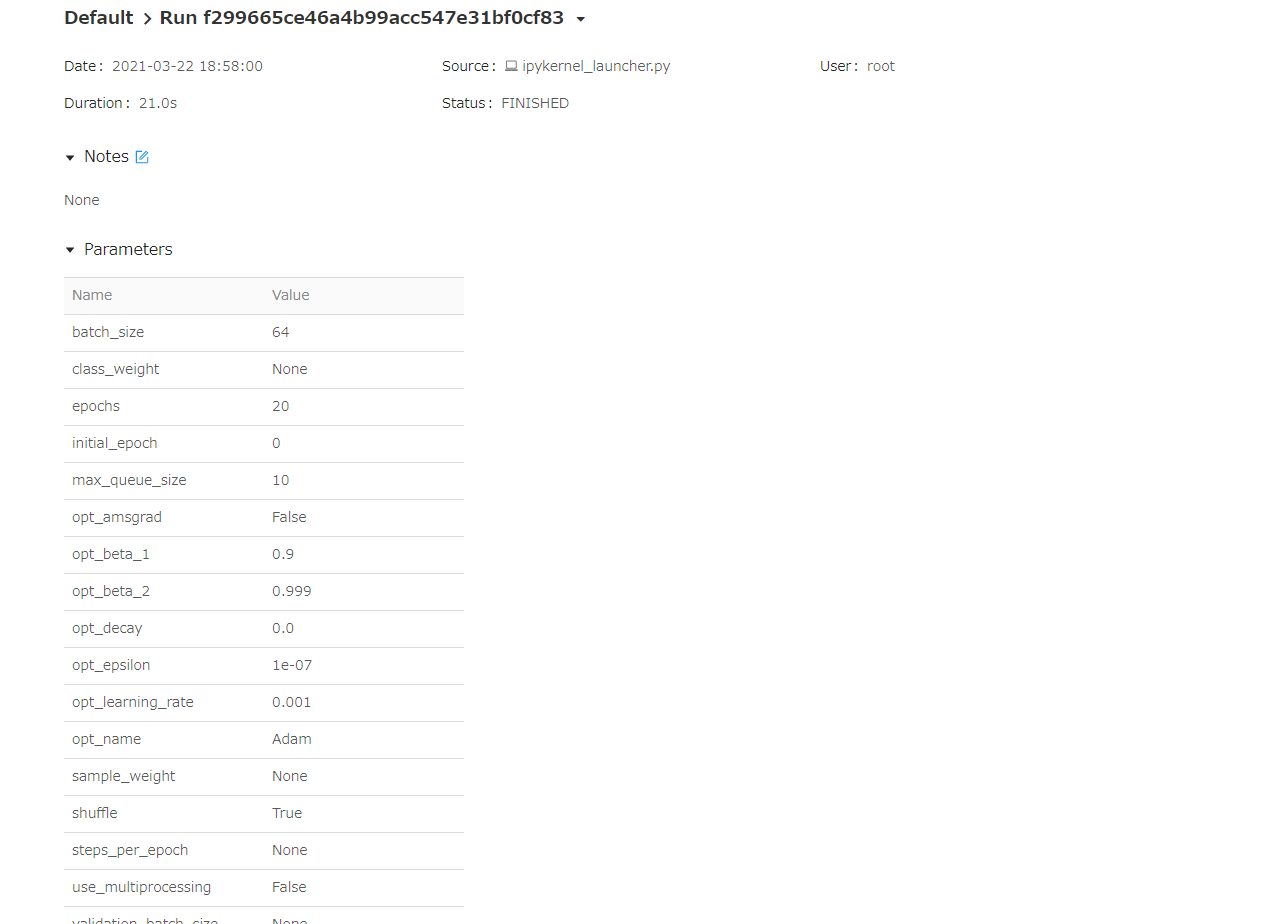
実験記録の詳細について、画像を並べていきます。 実験をクリックすることで実験パラメータの詳細を確認できます。 どのパラメータを記録するか、特に指定しなくても全て記録してくれるので非常に楽です。
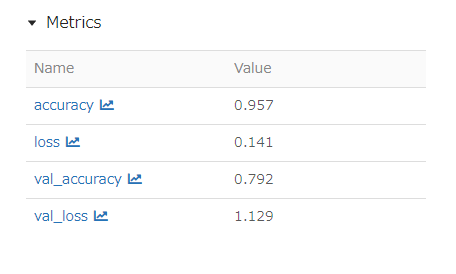
また、学習のメトリクスや学習曲線も確認できます。
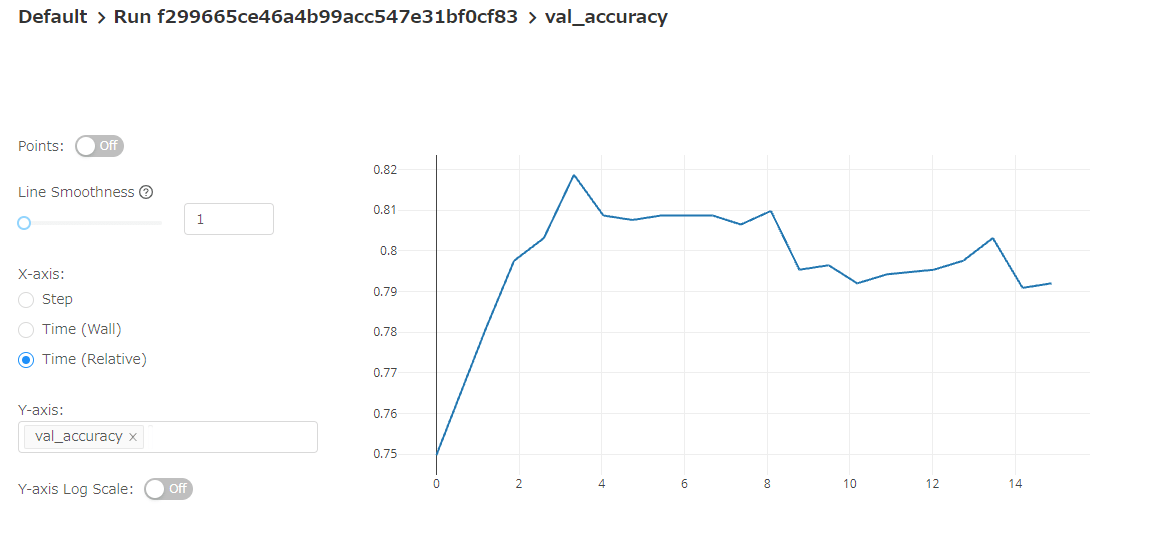
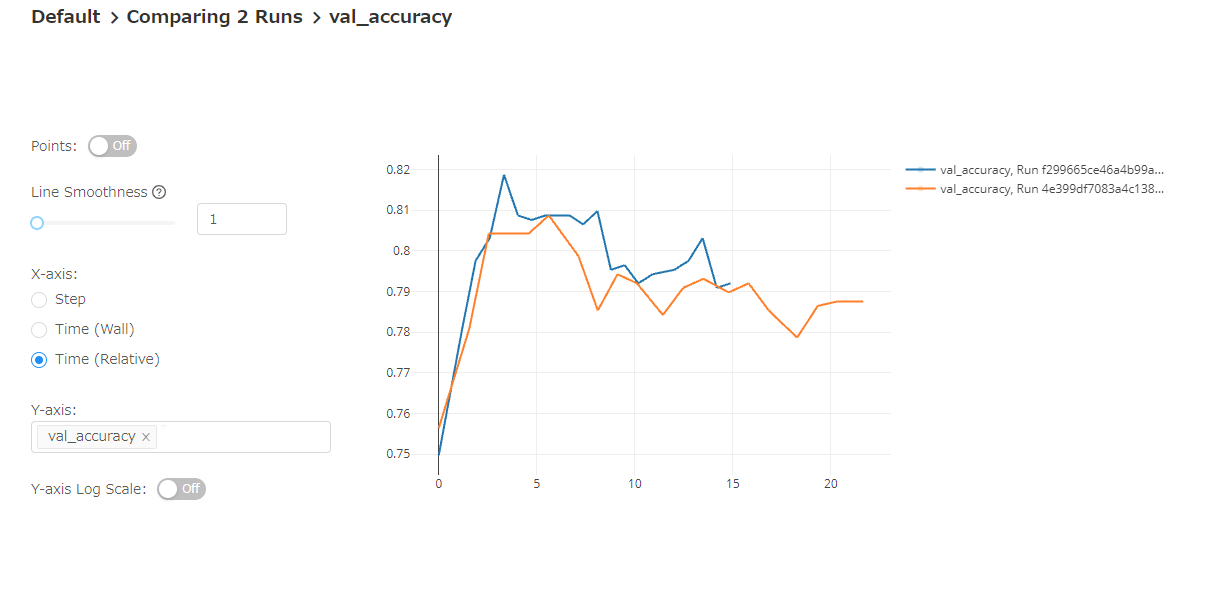
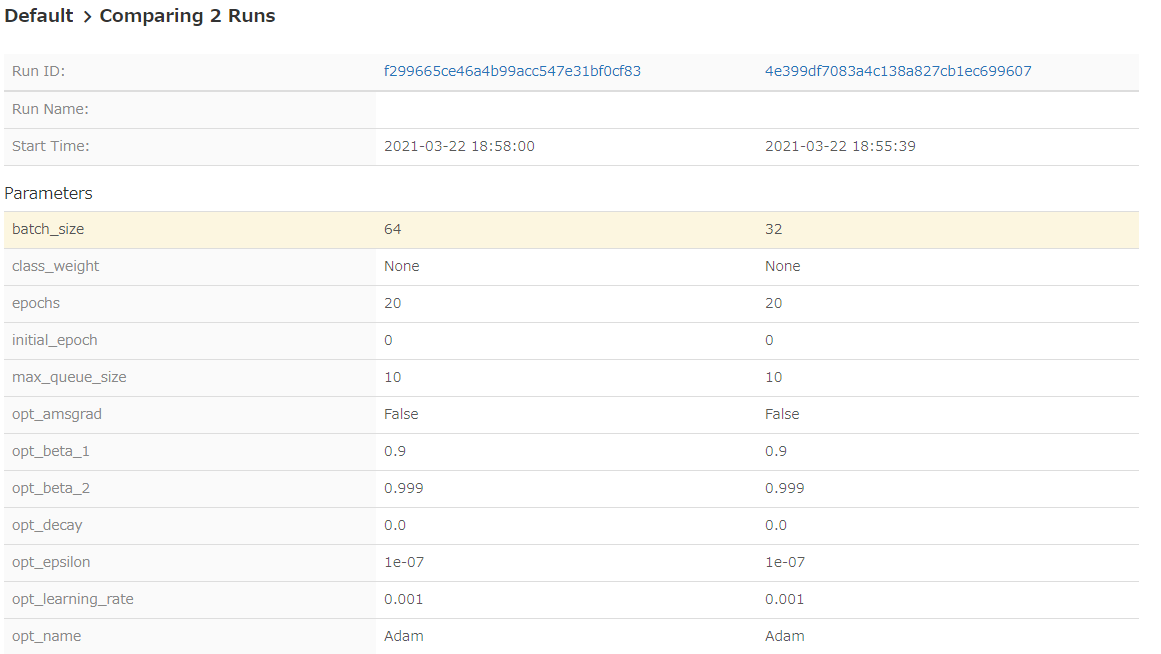
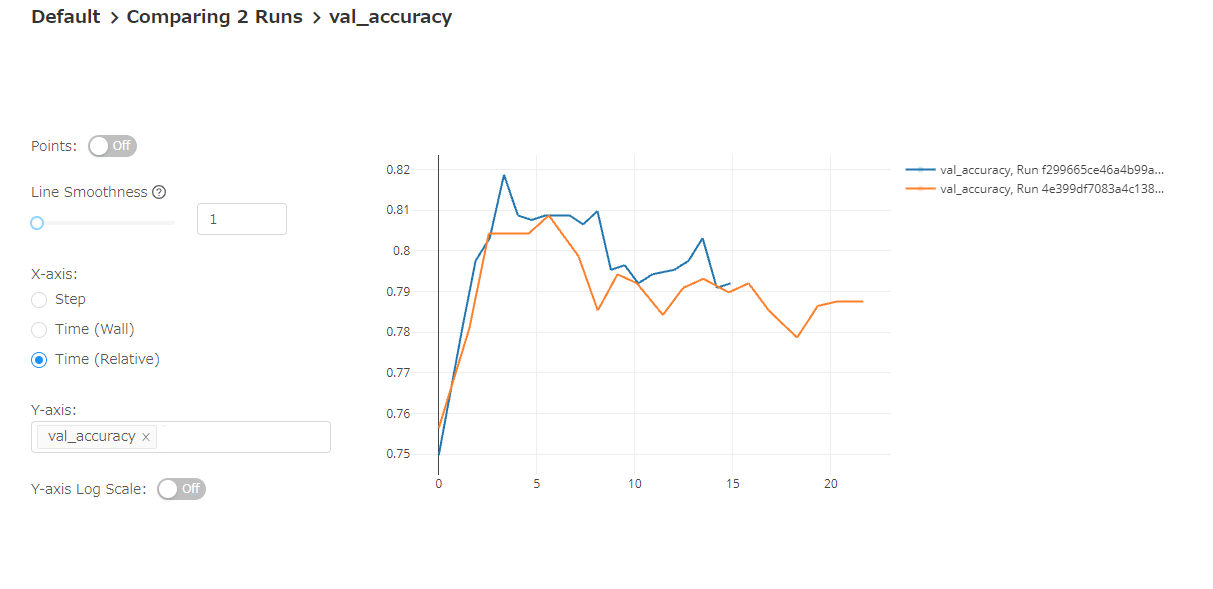
各実験を選んで、パラメータの比較も可能です。 パラメータが異なる部分はハイライトされます。 また、学習曲線についても比較可能です。
個人的に気に入っているのは、実験のメモが記述できることです。 実験のパラメータとそのメモが同じ場所に書けるので、ストレスが少ないです。
総括
MLflow は簡単な手順で機械学習の実験管理ができる便利ツールです。ほかにもモデルを自動で保存したり、公開するモデルを選択したりと便利な機能があるようなのですが、設定がうまくいっていないのかまだ使えていません。おそらくストレージの設定が原因。また挑戦してみます。 ライブラリって触ってみて分かることが多いと思うので、もし興味が沸いたらまずは触ってみてください。